Understanding Reasoning LLMs【译】
原文:Understanding Reasoning LLMs
This article describes the four main approaches to building reasoning models, or how we can enhance LLMs with reasoning capabilities. I hope this provides valuable insights and helps you navigate the rapidly evolving literature and hype surrounding this topic.
本文描述了构建推理模型的四种主要方法,或者说我们如何增强大型语言模型的推理能力。我希望这篇文章能提供有价值的见解,帮助您在快速发展的文献和围绕这个话题的炒作中找到方向。
In 2024, the LLM field saw increasing specialization. Beyond pre-training and fine-tuning, we witnessed the rise of specialized applications, from RAGs to code assistants. I expect this trend to accelerate in 2025, with an even greater emphasis on domain- and application-specific optimizations (i.e., “specializations”).
在 2024 年,大型语言模型领域见证了日益增长的专业化趋势。除了预训练和微调之外,我们还看到了专业应用的兴起,从 RAG(检索增强生成)到代码助手。我预计这种趋势将在 2025 年加速,更加强调特定领域和特定应用的优化(即“专业化”)。
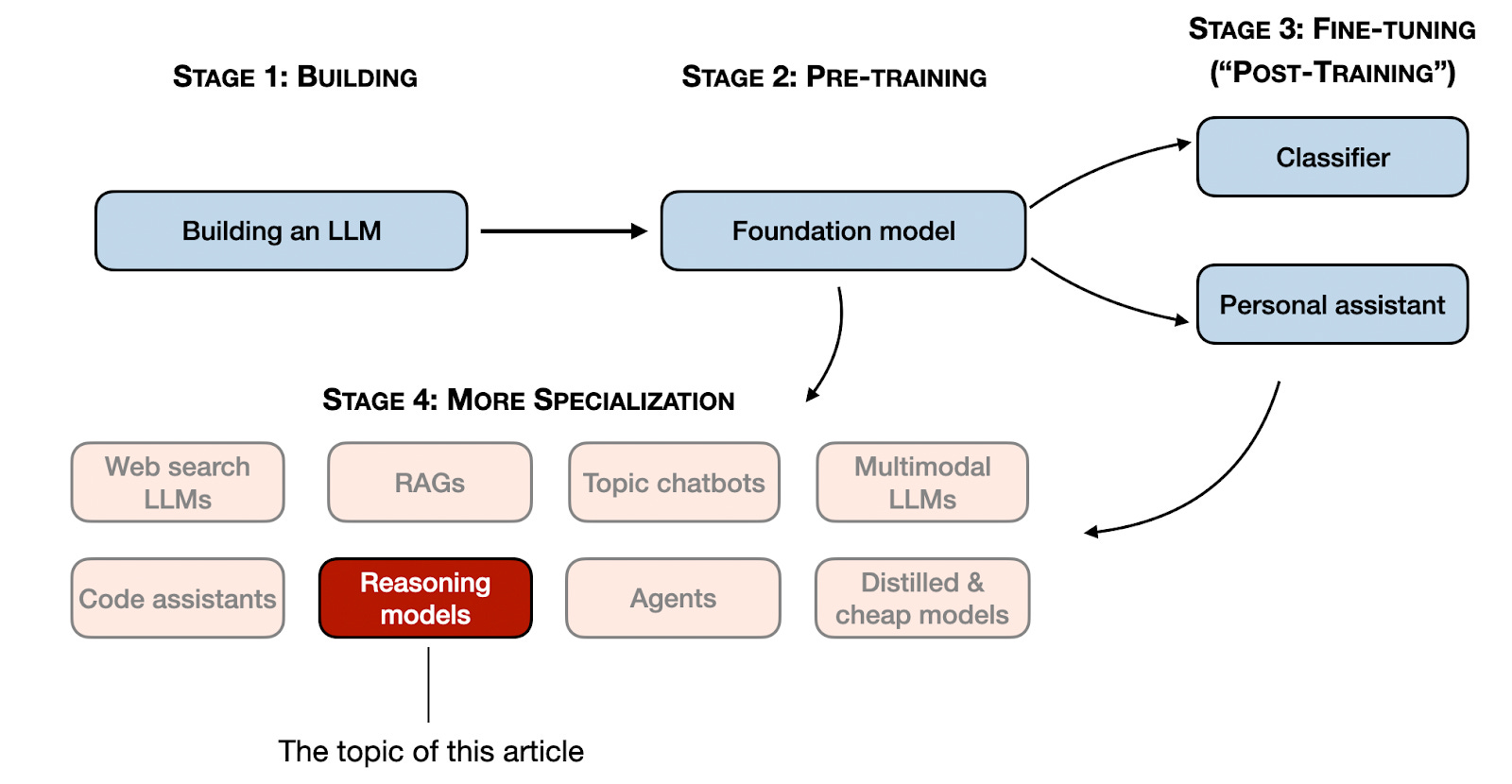
Stages 1-3 are the common steps to developing LLMs. Stage 4 specializes LLMs for specific use cases.
阶段 1-3 是开发大型语言模型的常用步骤。阶段 4 针对特定用例对大型语言模型进行专业化处理。
The development of reasoning models is one of these specializations. This means we refine LLMs to excel at complex tasks that are best solved with intermediate steps, such as puzzles, advanced math, and coding challenges. However, this specialization does not replace other LLM applications. Because transforming an LLM into a reasoning model also introduces certain drawbacks, which I will discuss later.
推理模型的开发是这些专业化领域之一。这意味着我们改进大型语言模型,使其擅长于通过中间步骤才能最好地解决的复杂任务,例如谜题、高等数学和编码挑战。然而,这种专业化并不会取代其他大型语言模型的应用。因为将大型语言模型转变为推理模型也会引入某些缺点,我将在后面讨论。
To give you a brief glimpse of what’s covered below, in this article, I will:
为了让您对下文内容有一个简要的了解,在本文中,我将:
Explain the meaning of “reasoning model”
解释“推理模型”的含义
Discuss the advantages and disadvantages of reasoning models
讨论推理模型的优点和缺点
Outline the methodology behind DeepSeek R1
概述 DeepSeek R1 背后的方法论
Describe the four main approaches to building and improving reasoning models
描述构建和改进推理模型的四种主要方法
Share thoughts on the LLM landscape following the DeepSeek V3 and R1 releases
分享在 DeepSeek V3 和 R1 发布后对大型语言模型格局的看法
Provide tips for developing reasoning models on a tight budget
提供在预算紧张的情况下开发推理模型的技巧
I hope you find this article useful as AI continues its rapid development this year!
我希望随着人工智能在今年继续快速发展,您会觉得这篇文章很有用!
If you work in AI (or machine learning in general), you are probably familiar with vague and hotly debated definitions. The term “reasoning models” is no exception. Eventually, someone will define it formally in a paper, only for it to be redefined in the next, and so on.
如果您从事人工智能(或广义上的机器学习)工作,您可能对模糊且备受争议的定义很熟悉。“推理模型”一词也不例外。最终,有人会在论文中正式定义它,但很快又会在下一篇论文中被重新定义,如此往复。
In this article, I define “reasoning” as the process of answering questions that require complex, multi-step generation with intermediate steps. For example, factual question-answering like “What is the capital of France?” does not involve reasoning. In contrast, a question like “If a train is moving at 60 mph and travels for 3 hours, how far does it go?” requires some simple reasoning. For instance, it requires recognizing the relationship between distance, speed, and time before arriving at the answer.
在本文中,我将“推理”定义为回答需要复杂、多步骤生成并带有中间步骤的问题的过程。例如,像“法国的首都是哪里?”这样的事实性问答不涉及推理。相比之下,像“如果一列火车以每小时 60 英里的速度行驶 3 小时,它行驶了多远?”这样的问题则需要一些简单的推理。例如,它需要在得出答案之前识别距离、速度和时间之间的关系。
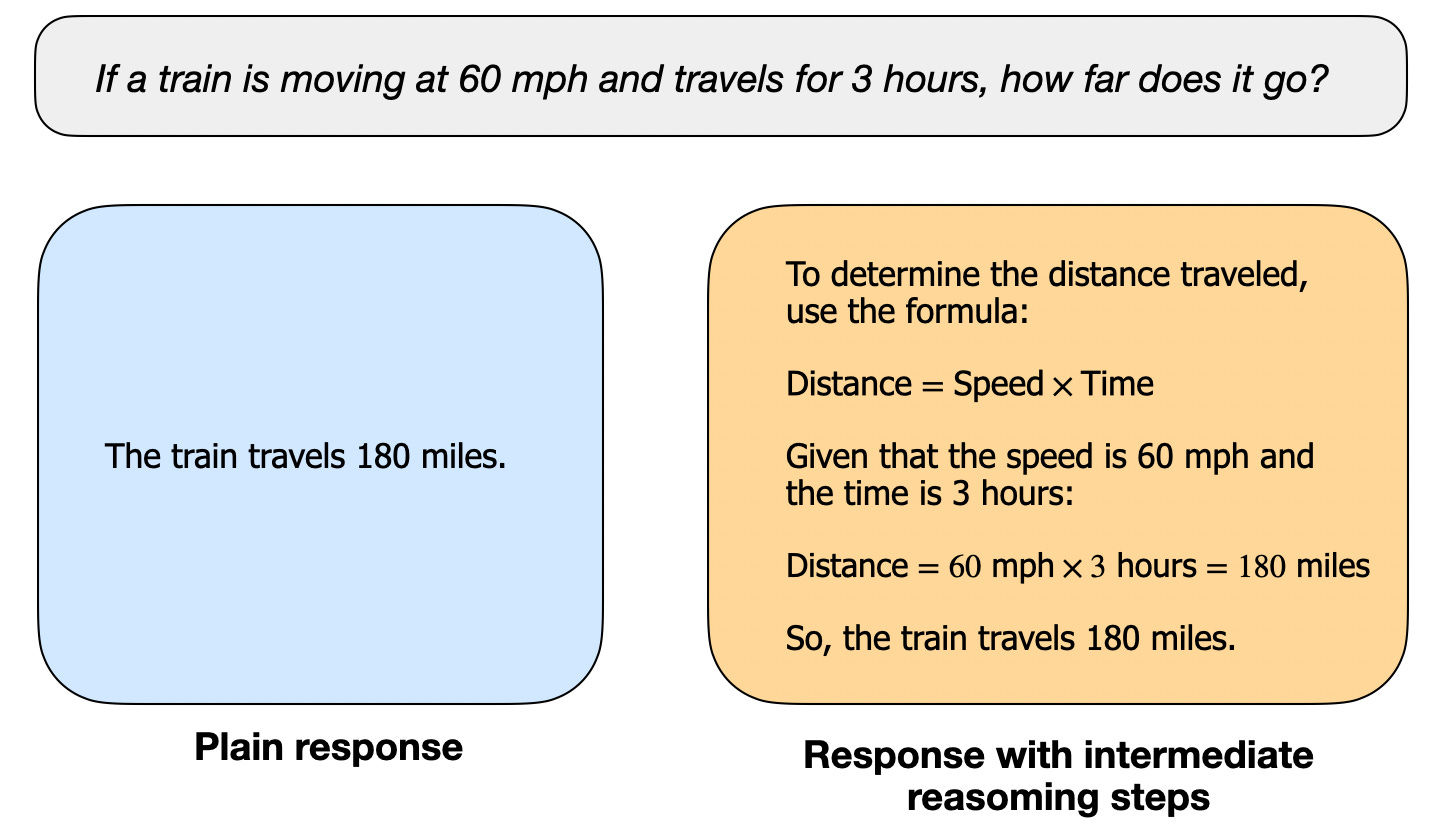
A regular LLM may only provide a short answer (as shown on the left), whereas reasoning models typically include intermediate steps that reveal part of the thought process. (Note that many LLMs who have not been specifically developed for reasoning tasks can also provide intermediate reasoning steps in their answers.)
一个普通的大型语言模型可能只提供一个简短的答案(如左图所示),而推理模型通常包括中间步骤,这些步骤揭示了部分思考过程。(请注意,许多未专门为推理任务开发的大型语言模型也可以在其答案中提供中间推理步骤。)
Most modern LLMs are capable of basic reasoning and can answer questions like, “If a train is moving at 60 mph and travels for 3 hours, how far does it go?” So, today, when we refer to reasoning models, we typically mean LLMs that excel at more complex reasoning tasks, such as solving puzzles, riddles, and mathematical proofs.
大多数现代大型语言模型都具备基本的推理能力,并且可以回答诸如“如果一列火车以每小时 60 英里的速度行驶 3 小时,它行驶了多远?”这样的问题。因此,今天当我们提到推理模型时,我们通常指的是擅长更复杂推理任务的大型语言模型,例如解决谜题、谜语和数学证明。
Additionally, most LLMs branded as reasoning models today include a “thought” or “thinking” process as part of their response. Whether and how an LLM actually “thinks” is a separate discussion.
此外,如今大多数被标榜为推理模型的大型语言模型,都将“思考”或“思维”过程作为其响应的一部分。大型语言模型是否以及如何真正“思考”是另一个单独的讨论。
Intermediate steps in reasoning models can appear in two ways. First, they may be explicitly included in the response, as shown in the previous figure. Second, some reasoning LLMs, such as OpenAI’s o1, run multiple iterations with intermediate steps that are not shown to the user.
推理模型中的中间步骤可以以两种方式出现。首先,它们可以像上图所示那样明确地包含在响应中。其次,一些推理大型语言模型,例如 OpenAI 的 o1,会运行多次迭代,其中间步骤不会显示给用户。
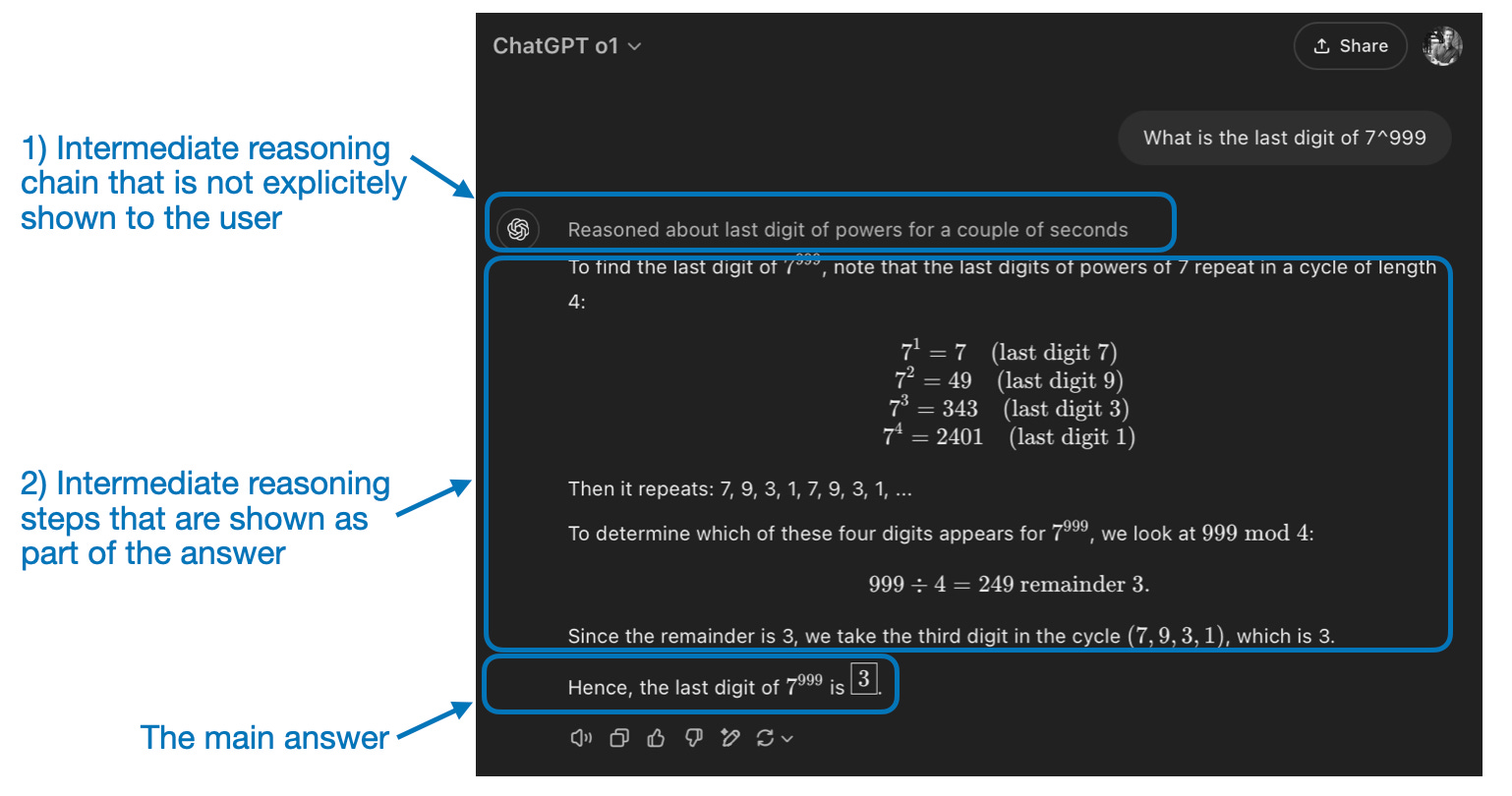
“Reasoning” is used at two different levels: 1) processing the input and generating via multiple intermediate steps and 2) providing some sort of reasoning as part of the response to the user.
“推理”在两个不同的层面使用:1)处理输入并通过多个中间步骤生成;2)提供某种推理作为给用户的响应的一部分。
Now that we have defined reasoning models, we can move on to the more interesting part: how to build and improve LLMs for reasoning tasks. However, before diving into the technical details, it is important to consider when reasoning models are actually needed.
现在我们已经定义了推理模型,我们可以继续讨论更有趣的部分:如何构建和改进用于推理任务的大型语言模型。然而,在深入探讨技术细节之前,重要的是要考虑何时真正需要推理模型。
When do we need a reasoning model? Reasoning models are designed to be good at complex tasks such as solving puzzles, advanced math problems, and challenging coding tasks. However, they are not necessary for simpler tasks like summarization, translation, or knowledge-based question answering. In fact, using reasoning models for everything can be inefficient and expensive. For instance, reasoning models are typically more expensive to use, more verbose, and sometimes more prone to errors due to “overthinking.” Also here the simple rule applies: Use the right tool (or type of LLM) for the task.
我们何时需要推理模型? 推理模型旨在擅长解决复杂任务,例如谜题、高等数学问题和具有挑战性的编码任务。然而,对于更简单的任务,例如摘要、翻译或基于知识的问答,它们并非必要。事实上,对所有任务都使用推理模型可能是低效且昂贵的。例如,推理模型通常使用起来更昂贵、更冗长,有时也更容易因“过度思考”而导致错误。这里也适用简单的规则:为任务选择合适的工具(或大型语言模型类型)。
The key strengths and limitations of reasoning models are summarized in the figure below.
推理模型的关键优势和局限性总结在下图中。

The key strengths and weaknesses of reasoning models.
推理模型的关键优势和劣势。
Before discussing four main approaches to building and improving reasoning models in the next section, I want to briefly outline the DeepSeek R1 pipeline, as described in the DeepSeek R1 technical report. This report serves as both an interesting case study and a blueprint for developing reasoning LLMs.
在下一节讨论构建和改进推理模型的四种主要方法之前,我想简要概述 DeepSeek R1 的流程,如 DeepSeek R1 技术报告 中所述。该报告既是一个有趣的案例研究,也是开发推理大型语言模型的蓝图。
Note that DeepSeek did not release a single R1 reasoning model but instead introduced three distinct variants: DeepSeek-R1-Zero, DeepSeek-R1, and DeepSeek-R1-Distill.
请注意,DeepSeek 没有发布单一的 R1 推理模型,而是推出了三种不同的变体:DeepSeek-R1-Zero、DeepSeek-R1 和 DeepSeek-R1-Distill。
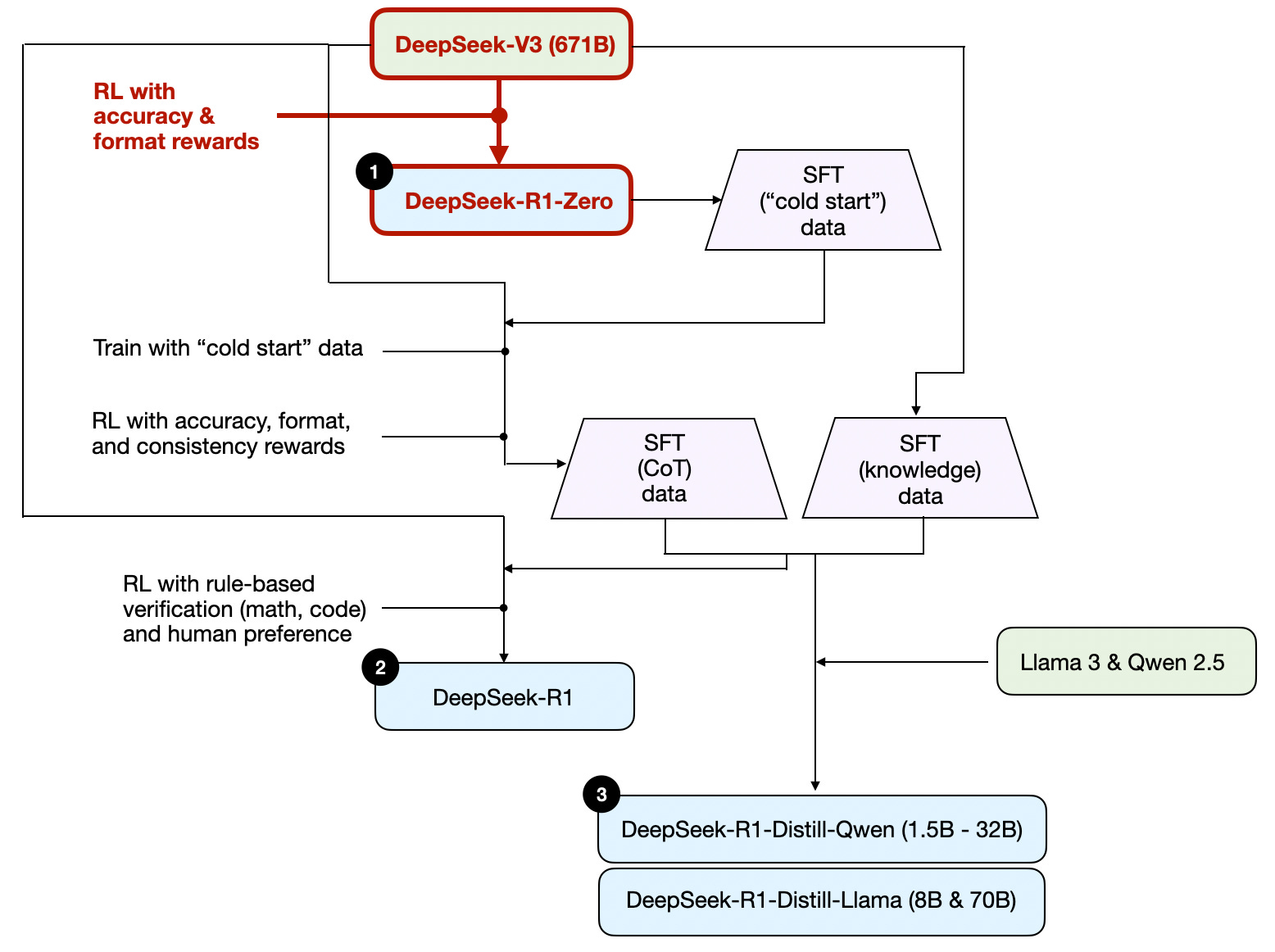
Based on the descriptions in the technical report, I have summarized the development process of these models in the diagram below.
根据技术报告中的描述,我在下图中总结了这些模型的开发过程。
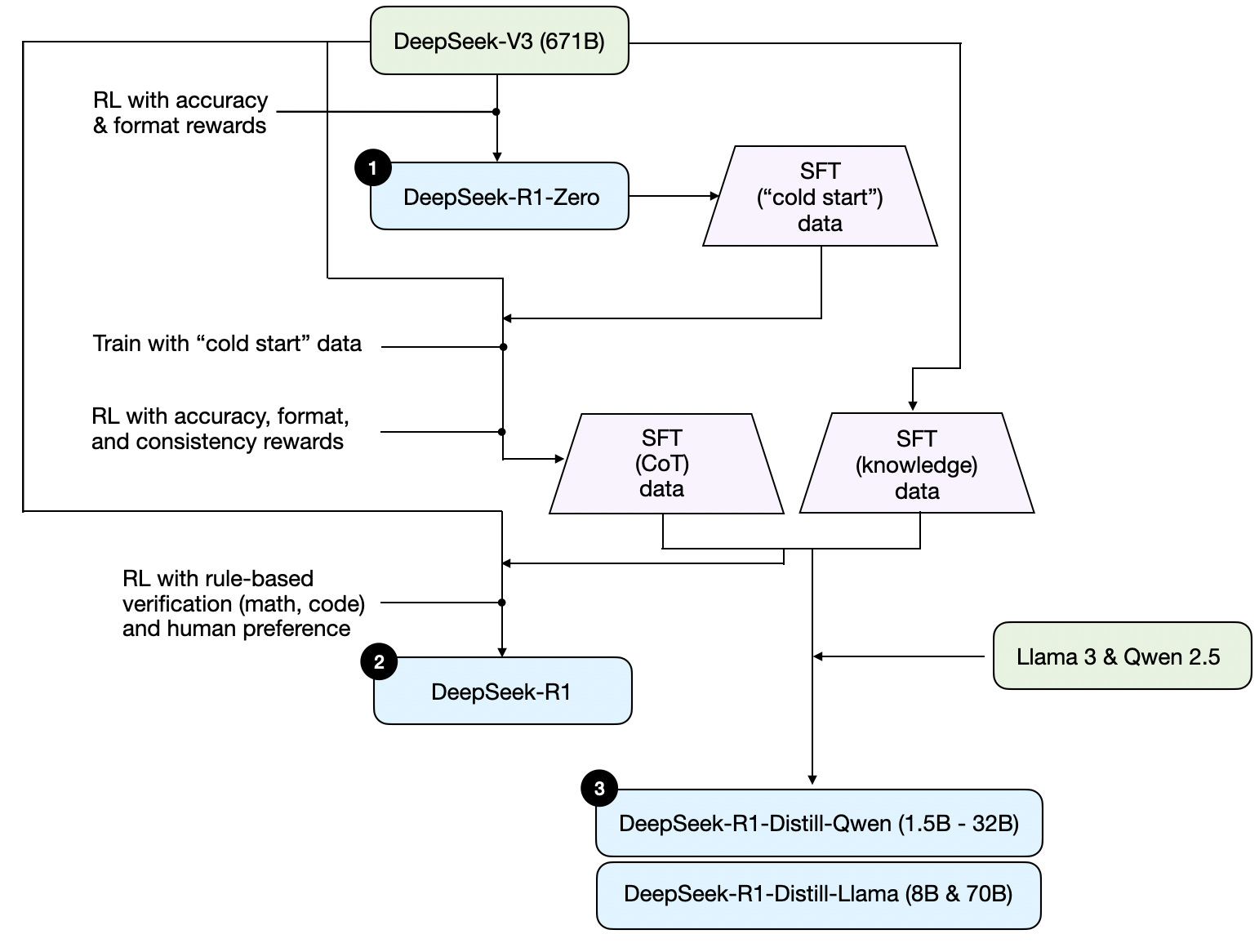
Development process of DeepSeeks three different reasoning models that are discussed in the DeepSeek R1 technical report.
DeepSeek R1 技术报告中讨论的 DeepSeek 三种不同推理模型的开发过程。
Next, let’s briefly go over the process shown in the diagram above. More details will be covered in the next section, where we discuss the four main approaches to building and improving reasoning models.
接下来,让我们简要回顾一下上图所示的过程。更多细节将在下一节中介绍,届时我们将讨论构建和改进推理模型的四种主要方法。
(1) DeepSeek-R1-Zero: This model is based on the 671B pre-trained DeepSeek-V3 base model released in December 2024. The research team trained it using reinforcement learning (RL) with two types of rewards. This approach is referred to as “cold start” training because it did not include a supervised fine-tuning (SFT) step, which is typically part of reinforcement learning with human feedback (RLHF).
(1) DeepSeek-R1-Zero: 该模型基于 2024 年 12 月发布的 671B 预训练 DeepSeek-V3 基础模型。研究团队使用强化学习 (RL) 和两种类型的奖励对其进行了训练。这种方法被称为“冷启动”训练,因为它不包括监督微调 (SFT) 步骤,而监督微调通常是基于人类反馈的强化学习 (RLHF) 的一部分。
(2) DeepSeek-R1: This is DeepSeek’s flagship reasoning model, built upon DeepSeek-R1-Zero. The team further refined it with additional SFT stages and further RL training, improving upon the “cold-started” R1-Zero model.
(2) DeepSeek-R1: 这是 DeepSeek 的旗舰推理模型,建立在 DeepSeek-R1-Zero 之上。团队通过额外的 SFT 阶段和进一步的 RL 训练对其进行了进一步改进,从而改进了“冷启动”的 R1-Zero 模型。
(3) DeepSeek-R1-Distill*: Using the SFT data generated in the previous steps, the DeepSeek team fine-tuned Qwen and Llama models to enhance their reasoning abilities. While not distillation in the traditional sense, this process involved training smaller models (Llama 8B and 70B, and Qwen 1.5B–30B) on outputs from the larger DeepSeek-R1 671B model.
(3) DeepSeek-R1-Distill*: DeepSeek 团队使用前几个步骤中生成的 SFT 数据,对 Qwen 和 Llama 模型进行了微调,以增强它们的推理能力。虽然不是传统意义上的蒸馏,但这个过程涉及到使用来自更大的 DeepSeek-R1 671B 模型的输出来训练较小的模型(Llama 8B 和 70B,以及 Qwen 1.5B–30B)。
In this section, I will outline the key techniques currently used to enhance the reasoning capabilities of LLMs and to build specialized reasoning models such as DeepSeek-R1, OpenAI’s o1 & o3, and others.
在本节中,我将概述当前用于增强大型语言模型的推理能力以及构建专门的推理模型(例如 DeepSeek-R1、OpenAI 的 o1 和 o3 等)的关键技术。
Note: The exact workings of o1 and o3 remain unknown outside of OpenAI. However, they are rumored to leverage a combination of both inference and training techniques.
注意:o1 和 o3 的确切工作原理在 OpenAI 之外仍然未知。然而,有传言称它们利用了推理和训练技术的结合。
One way to improve an LLM’s reasoning capabilities (or any capability in general) is inference-time scaling. This term can have multiple meanings, but in this context, it refers to increasing computational resources during inference to improve output quality.
提高大型语言模型推理能力(或任何能力)的一种方法是推理时扩展。这个术语可以有多种含义,但在本文中,它指的是在推理期间增加计算资源以提高输出质量。
A rough analogy is how humans tend to generate better responses when given more time to think through complex problems. Similarly, we can apply techniques that encourage the LLM to “think” more while generating an answer. (Although, whether LLMs actually “think” is a different discussion.)
一个粗略的类比是,当人类有更多时间思考复杂问题时,往往会产生更好的响应。同样,我们可以应用一些技术来鼓励大型语言模型在生成答案时“思考”更多。(尽管,大型语言模型是否真的“思考”是另一个不同的讨论。)
One straightforward approach to inference-time scaling is clever prompt engineering. A classic example is chain-of-thought (CoT) prompting, where phrases like “think step by step” are included in the input prompt. This encourages the model to generate intermediate reasoning steps rather than jumping directly to the final answer, which can often (but not always) lead to more accurate results on more complex problems. (Note that it doesn’t make sense to employ this strategy for simpler knowledge-based questions, like “What is the capital of France”, which is again a good rule of thumb to find out whether a reasoning model makes sense on your given input query.)
一种直接的推理时扩展方法是巧妙的提示工程。一个经典的例子是_思维链 (CoT) 提示_,其中在输入提示中包含诸如“逐步思考”之类的短语。这鼓励模型生成中间推理步骤,而不是直接跳到最终答案,这通常(但并非总是)可以在更复杂的问题上产生更准确的结果。(请注意,对于更简单的基于知识的问题,例如“法国的首都是哪里?”,采用这种策略是没有意义的,这再次是一个很好的经验法则,可以判断推理模型在您给定的输入查询中是否有意义。)

An example of classic CoT prompting from the 2022 Large Language Models are Zero-Shot Reasoners paper (https://arxiv.org/abs/2205.11916).
2022 年论文《大型语言模型是零样本推理器》(https://arxiv.org/abs/2205.11916) 中经典 CoT 提示的一个示例。
The aforementioned CoT approach can be seen as inference-time scaling because it makes inference more expensive through generating more output tokens.
上述 CoT 方法可以被视为推理时扩展,因为它通过生成更多输出令牌使推理成本更高。
Another approach to inference-time scaling is the use of voting and search strategies. One simple example is majority voting where we have the LLM generate multiple answers, and we select the correct answer by majority vote. Similarly, we can use beam search and other search algorithms to generate better responses.
推理时扩展的另一种方法是使用投票和搜索策略。一个简单的例子是多数投票,我们让大型语言模型生成多个答案,然后通过多数投票选择正确答案。同样,我们可以使用束搜索和其他搜索算法来生成更好的响应。
I highly recommend the Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters paper that I described in my previous Noteworthy AI Research Papers of 2024 (Part Two) article (https://magazine.sebastianraschka.com/p/ai-research-papers-2024-part-2) for more details on these different strategies.
我强烈推荐我在之前的 2024 年值得关注的人工智能研究论文(第二部分)文章 (https://magazine.sebastianraschka.com/p/ai-research-papers-2024-part-2) 中描述的论文 _优化扩展大型语言模型测试时计算可能比扩展模型参数更有效_,以了解有关这些不同策略的更多详细信息。
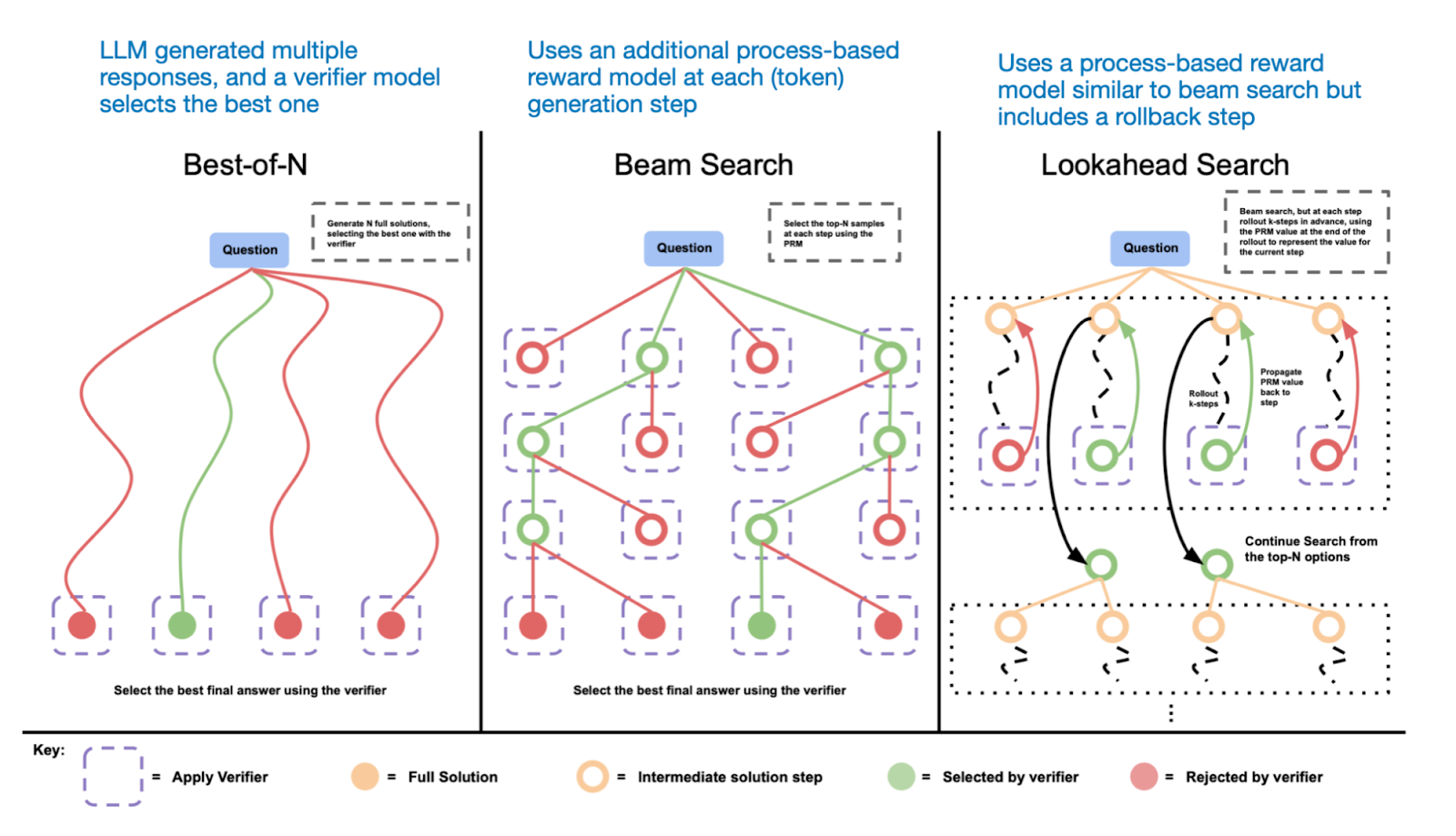
Different search-based methods rely on a process-reward-based model to select the best answer. Annotated figure from the LLM Test-Time Compute paper, https://arxiv.org/abs/2408.03314
不同的基于搜索的方法依赖于基于过程-奖励的模型来选择最佳答案。来自大型语言模型测试时计算论文的注释图,https://arxiv.org/abs/2408.03314
The DeepSeek R1 technical report states that its models do not use inference-time scaling. However, this technique is often implemented at the application layer on top of the LLM, so it is possible that DeepSeek applies it within their app.
DeepSeek R1 技术报告指出,其模型不使用推理时扩展。然而,这种技术通常在大型语言模型之上的应用层实现,因此 DeepSeek 可能在其应用程序中应用了它。
I suspect that OpenAI’s o1 and o3 models use inference-time scaling, which would explain why they are relatively expensive compared to models like GPT-4o. In addition to inference-time scaling, o1 and o3 were likely trained using RL pipelines similar to those used for DeepSeek R1. More on reinforcement learning in the next two sections below.
我怀疑 OpenAI 的 o1 和 o3 模型使用了推理时扩展,这可以解释为什么与 GPT-4o 等模型相比,它们相对昂贵。除了推理时扩展之外,o1 和 o3 很可能还使用了类似于 DeepSeek R1 使用的 RL 流程进行训练。有关强化学习的更多信息,请参见下文的两个部分。
One of my personal highlights from the DeepSeek R1 paper is their discovery that reasoning emerges as a behavior from pure reinforcement learning (RL). Let’s explore what this means in more detail.
DeepSeek R1 论文 中我个人最喜欢的部分之一是他们的发现,即推理作为一种行为从纯强化学习 (RL) 中涌现出来。让我们更详细地探讨一下这意味着什么。
As outlined earlier, DeepSeek developed three types of R1 models. The first, DeepSeek-R1-Zero, was built on top of the DeepSeek-V3 base model, a standard pre-trained LLM they released in December 2024. Unlike typical RL pipelines, where supervised fine-tuning (SFT) is applied before RL, DeepSeek-R1-Zero was trained exclusively with reinforcement learning without an initial SFT stage as highlighted in the diagram below.
如前所述,DeepSeek 开发了三种类型的 R1 模型。第一个是 DeepSeek-R1-Zero,它建立在 DeepSeek-V3 基础模型之上,这是他们在 2024 年 12 月发布的标准预训练大型语言模型。与典型的 RL 流程(在 RL 之前应用监督微调 (SFT))不同,DeepSeek-R1-Zero 完全 使用强化学习进行训练,而没有初始 SFT 阶段,如下图所示突出显示。
The development process of DeepSeek-R1-Zero model.
DeepSeek-R1-Zero 模型的开发过程。
Still, this RL process is similar to the commonly used RLHF approach, which is typically applied to preference-tune LLMs. (I covered RLHF in more detail in my article, LLM Training: RLHF and Its Alternatives.) However, as mentioned above, the key difference in DeepSeek-R1-Zero is that they skipped the supervised fine-tuning (SFT) stage for instruction tuning. This is why they refer to it as “pure” RL. (Although, RL in the context of LLMs differs significantly from traditional RL, which is a topic for another time.)
尽管如此,这种 RL 过程类似于常用的 RLHF 方法,该方法通常应用于偏好调整大型语言模型。(我在我的文章 大型语言模型训练:RLHF 及其替代方案 中更详细地介绍了 RLHF。)然而,如上所述,DeepSeek-R1-Zero 的关键区别在于,他们跳过了用于指令调整的监督微调 (SFT) 阶段。这就是他们将其称为“纯粹” RL 的原因。(虽然,大型语言模型背景下的 RL 与传统 RL 有很大不同,这是另一个话题。)
For rewards, instead of using a reward model trained on human preferences, they employed two types of rewards: an accuracy reward and a format reward.
对于奖励,他们没有使用基于人类偏好训练的奖励模型,而是采用了两种类型的奖励:准确性奖励和格式奖励。
The accuracy reward uses the LeetCode compiler to verify coding answers and a deterministic system to evaluate mathematical responses.
准确性奖励 使用 LeetCode 编译器来验证编码答案,并使用确定性系统来评估数学响应。
The format reward relies on an LLM judge to ensure responses follow the expected format, such as placing reasoning steps inside <think> tags.
格式奖励 依赖于大型语言模型判断器,以确保响应遵循预期的格式,例如将推理步骤放在 <think> 标签内。
Surprisingly, this approach was enough for the LLM to develop basic reasoning skills. The researchers observed an “Aha!” moment, where the model began generating reasoning traces as part of its responses despite not being explicitly trained to do so, as shown in the figure below.
令人惊讶的是,这种方法足以让大型语言模型发展出基本的推理技能。研究人员观察到了一个“Aha!”时刻,模型开始在其响应中生成推理轨迹,尽管没有明确训练这样做,如下图所示。

A figure from the DeepSeek R1 technical report (https://arxiv.org/abs/2501.12948) showing the emergence of the “Aha” moment.
来自 DeepSeek R1 技术报告 (https://arxiv.org/abs/2501.12948) 的图,显示了“Aha”时刻的出现。
While R1-Zero is not a top-performing reasoning model, it does demonstrate reasoning capabilities by generating intermediate “thinking” steps, as shown in the figure above. This confirms that it is possible to develop a reasoning model using pure RL, and the DeepSeek team was the first to demonstrate (or at least publish) this approach.
虽然 R1-Zero 不是性能最佳的推理模型,但它确实通过生成中间的“思考”步骤来展示推理能力,如上图所示。这证实了使用纯粹的 RL 开发推理模型是可能的,而 DeepSeek 团队是第一个展示(或至少发布)这种方法的团队。
Next, let’s look at the development of DeepSeek-R1, DeepSeek’s flagship reasoning model, which serves as a blueprint for building reasoning models. This model improves upon DeepSeek-R1-Zero by incorporating additional supervised fine-tuning (SFT) and reinforcement learning (RL) to improve its reasoning performance.
接下来,让我们看看 DeepSeek-R1(DeepSeek 的旗舰推理模型)的开发,它为构建推理模型提供了蓝图。该模型通过结合额外的监督微调 (SFT) 和强化学习 (RL) 来改进 DeepSeek-R1-Zero,从而提高其推理性能。
Note that it is actually common to include an SFT stage before RL, as seen in the standard RLHF pipeline. OpenAI’s o1 was likely developed using a similar approach.
请注意,实际上在 RL 之前包含 SFT 阶段是很常见的,正如在标准的 RLHF 流程中所见。OpenAI 的 o1 很可能使用类似的方法开发。
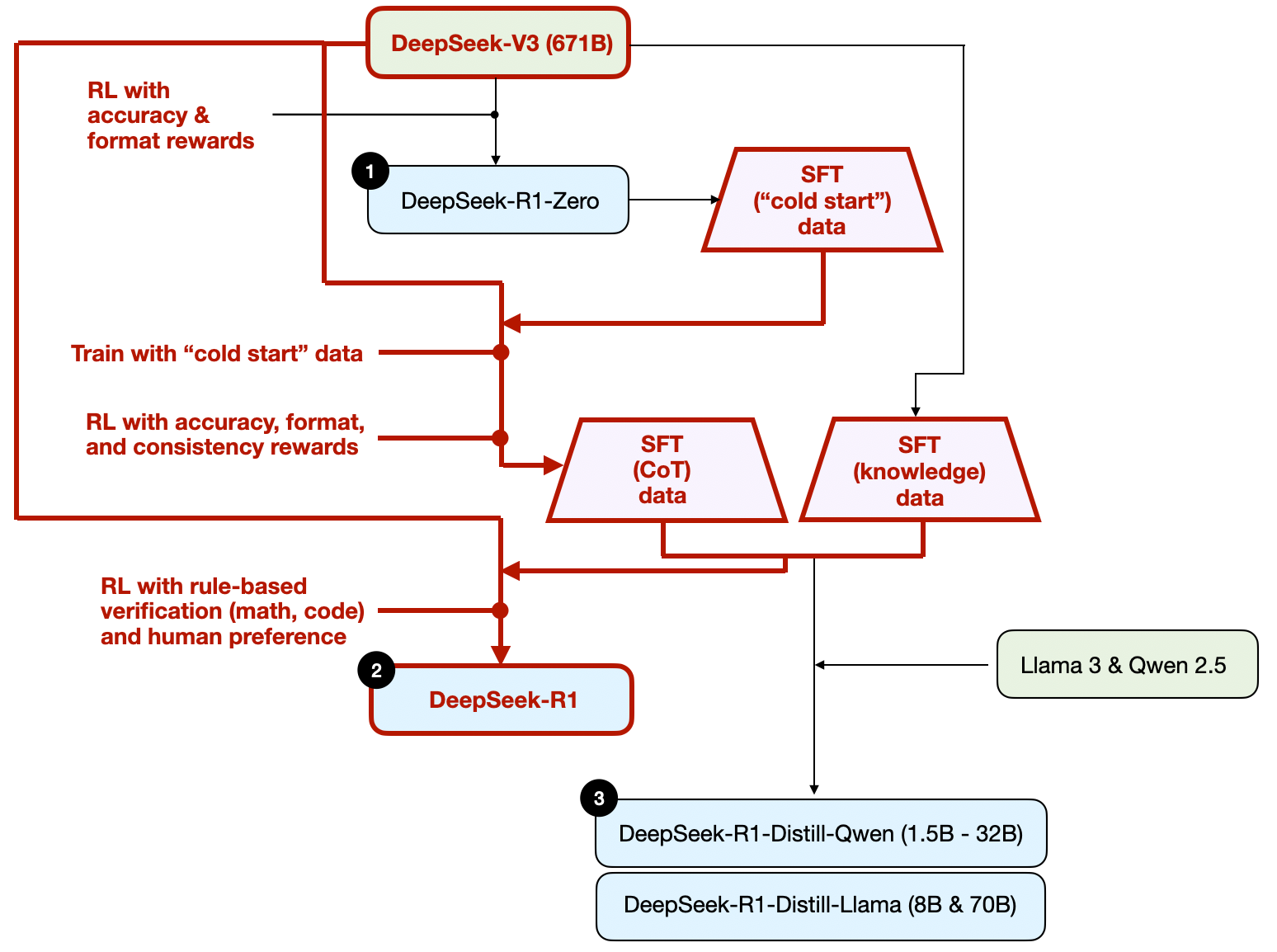
The development process of DeepSeek-R1 model.
DeepSeek-R1 模型的开发过程。
As shown in the diagram above, the DeepSeek team used DeepSeek-R1-Zero to generate what they call “cold-start” SFT data. The term “cold start” refers to the fact that this data was produced by DeepSeek-R1-Zero, which itself had not been trained on any supervised fine-tuning (SFT) data.
如上图所示,DeepSeek 团队使用 DeepSeek-R1-Zero 生成了他们所谓的“冷启动”SFT 数据。“冷启动”一词指的是该数据由 DeepSeek-R1-Zero 生成,而 DeepSeek-R1-Zero 本身没有在任何监督微调 (SFT) 数据上进行过训练。
Using this cold-start SFT data, DeepSeek then trained the model via instruction fine-tuning, followed by another reinforcement learning (RL) stage. This RL stage retained the same accuracy and format rewards used in DeepSeek-R1-Zero’s RL process. However, they added a consistency reward to prevent language mixing, which occurs when the model switches between multiple languages within a response.
DeepSeek 使用此冷启动 SFT 数据,然后通过指令微调训练模型,随后是另一个强化学习 (RL) 阶段。此 RL 阶段保留了 DeepSeek-R1-Zero 的 RL 过程中使用的相同准确性和格式奖励。但是,他们添加了一致性奖励,以防止语言混合,当模型在响应中在多种语言之间切换时会发生语言混合。
The RL stage was followed by another round of SFT data collection. In this phase, the most recent model checkpoint was used to generate 600K Chain-of-Thought (CoT) SFT examples, while an additional 200K knowledge-based SFT examples were created using the DeepSeek-V3 base model.
在 RL 阶段之后,又进行了一轮 SFT 数据收集。在此阶段,最新的模型检查点用于生成 60 万个思维链 (CoT) SFT 示例,同时使用 DeepSeek-V3 基础模型创建了额外的 20 万个基于知识的 SFT 示例。
These 600K + 200K SFT samples were then used for instruction-finetuning DeepSeek-V3 base before following up with a final round of RL. In this stage, they again used rule-based methods for accuracy rewards for math and coding questions, while human preference labels used for other question types. All in all, this is very similar to regular RLHF except that the SFT data contains (more) CoT examples. And the RL has verifiable rewards in addition to human preference-based rewards.
然后,在进行最后一轮 RL 之前,这些 60 万 + 20 万个 SFT 样本用于指令微调 DeepSeek-V3 基础模型。在此阶段,他们再次使用基于规则的方法来奖励数学和编码问题的准确性,而对于其他问题类型,则使用人类偏好标签。总而言之,这与常规 RLHF 非常相似,只是 SFT 数据包含(更多)CoT 示例。并且 RL 除了基于人类偏好的奖励外,还具有可验证的奖励。
The final model, DeepSeek-R1 has a noticeable performance boost over DeepSeek-R1-Zero thanks to the additional SFT and RL stages, as shown in the table below.
最终模型 DeepSeek-R1 由于额外的 SFT 和 RL 阶段,与 DeepSeek-R1-Zero 相比,性能显着提升,如下表所示。
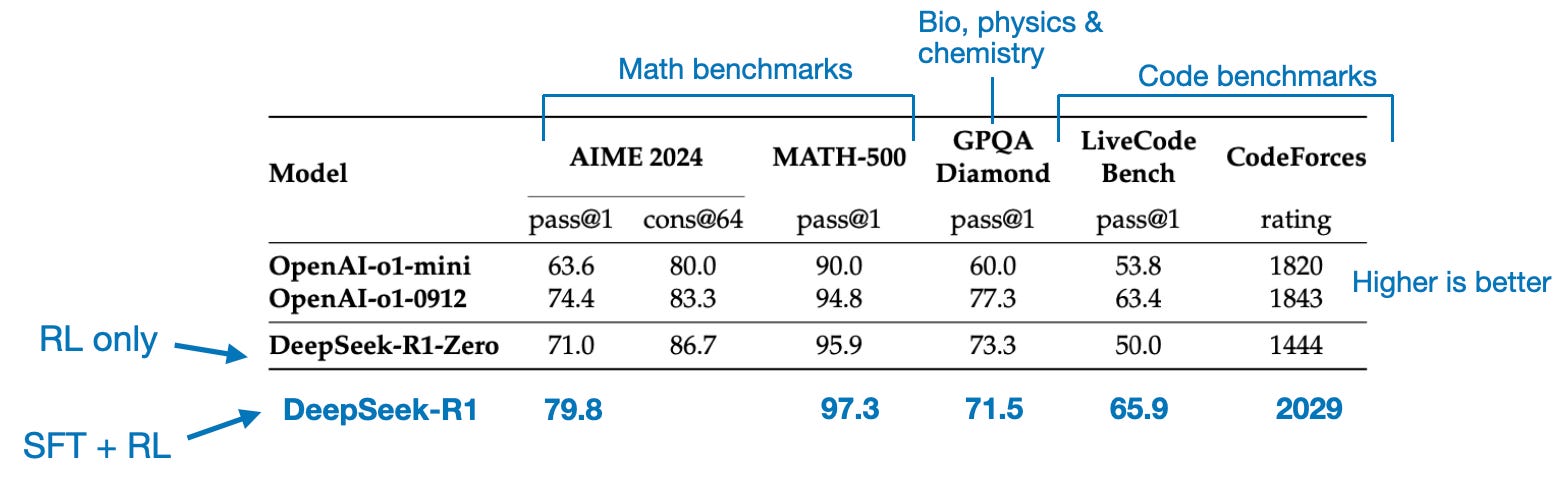
Benchmark comparison of OpenAI A1 and DeepSeek R1 models. Annotated figure from the DeepSeek-R1 technical report (https://arxiv.org/abs/2501.12948).
OpenAI A1 和 DeepSeek R1 模型的基准比较。来自 DeepSeek-R1 技术报告 (https://arxiv.org/abs/2501.12948) 的注释图。
So far, we have covered three key approaches to building and improving reasoning models:
到目前为止,我们已经介绍了构建和改进推理模型的三种关键方法:
1. Inference-time scaling, a technique that improves reasoning capabilities without training or otherwise modifying the underlying model.
- 推理时扩展,这是一种无需训练或以其他方式修改底层模型即可提高推理能力的技术。
2. Pure reinforcement learning (RL) as in DeepSeek-R1-Zero, which showed that reasoning can emerge as a learned behavior without supervised fine-tuning.
- 纯强化学习 (RL),如 DeepSeek-R1-Zero 中所示,它表明推理可以作为一种学习行为在没有监督微调的情况下出现。
3. Supervised fine-tuning (SFT) plus RL, which led to DeepSeek-R1, DeepSeek’s flagship reasoning model.
- 监督微调 (SFT) 加 RL,这导致了 DeepSeek-R1,DeepSeek 的旗舰推理模型。
So, what’s left? Model “distillation.”
那么,还剩下什么?模型“蒸馏”。
Surprisingly, DeepSeek also released smaller models trained via a process they call distillation. However, in the context of LLMs, distillation does not necessarily follow the classical knowledge distillation approach used in deep learning. Traditionally, in knowledge distillation (as briefly described in Chapter 6 of my Machine Learning Q and AI book), a smaller student model is trained on both the logits of a larger teacher model and a target dataset.
令人惊讶的是,DeepSeek 还发布了通过他们称为_蒸馏_的过程训练的较小模型。然而,在大型语言模型的背景下,蒸馏不一定遵循深度学习中使用的经典知识蒸馏方法。传统上,在知识蒸馏中(如我的 机器学习问答 一书的第 6 章中简要描述的那样),较小的学生模型在较大的教师模型的 logits 和目标数据集上进行训练。
Instead, here distillation refers to instruction fine-tuning smaller LLMs, such as Llama 8B and 70B and Qwen 2.5 models (0.5B to 32B), on an SFT dataset generated by larger LLMs. Specifically, these larger LLMs are DeepSeek-V3 and an intermediate checkpoint of DeepSeek-R1. In fact, the SFT data used for this distillation process is the same dataset that was used to train DeepSeek-R1, as described in the previous section.
相反,这里的蒸馏指的是在由更大的大型语言模型生成的 SFT 数据集上对较小的大型语言模型(例如 Llama 8B 和 70B 以及 Qwen 2.5 模型(0.5B 到 32B))进行指令微调。具体来说,这些更大的大型语言模型是 DeepSeek-V3 和 DeepSeek-R1 的中间检查点。事实上,用于此蒸馏过程的 SFT 数据与用于训练 DeepSeek-R1 的数据集相同,如上一节所述。
To clarify this process, I have highlighted the distillation portion in the diagram below.
为了澄清这个过程,我在下图中突出显示了蒸馏部分。
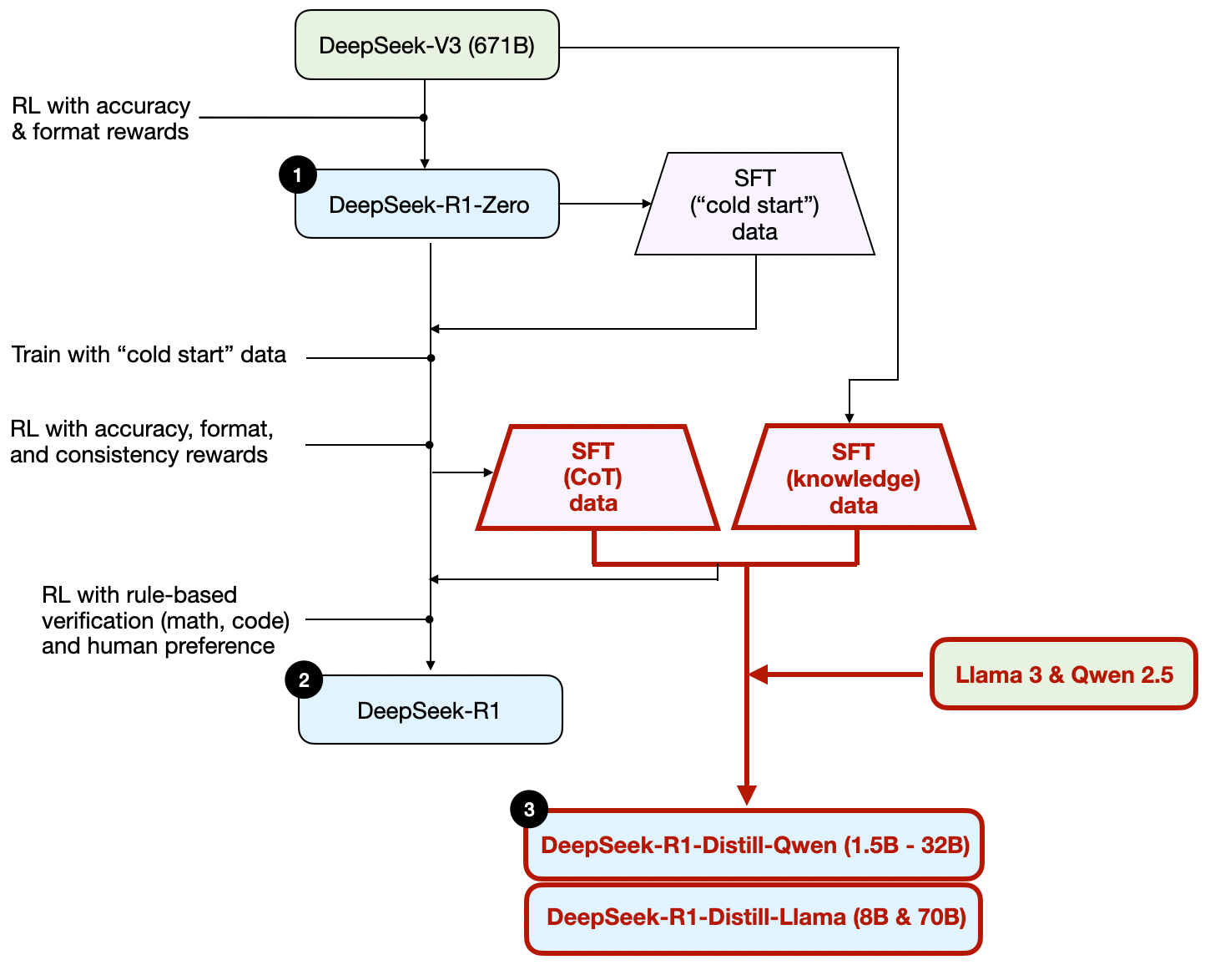
The development process of DeepSeek-R1-Distill models.
DeepSeek-R1-Distill 模型的开发过程。
Why did they develop these distilled models? In my opinion, there are two key reasons:
他们为什么要开发这些蒸馏模型?在我看来,有两个关键原因:
1. Smaller models are more efficient. This means they are cheaper to run, but they also can run on lower-end hardware, which makes these especially interesting for many researchers and tinkerers like me.
- 较小的模型更高效。这意味着它们运行起来更便宜,而且它们也可以在低端硬件上运行,这使得它们对于许多研究人员和像我这样的修补匠来说特别有趣。
2. A case study in pure SFT. These distilled models serve as an interesting benchmark, showing how far pure supervised fine-tuning (SFT) can take a model without reinforcement learning.
- 纯 SFT 的案例研究。这些蒸馏模型充当了一个有趣的基准,展示了在没有强化学习的情况下,纯监督微调 (SFT) 可以将模型提升到什么程度。
The table below compares the performance of these distilled models against other popular models, as well as DeepSeek-R1-Zero and DeepSeek-R1.
下表比较了这些蒸馏模型与其他流行模型以及 DeepSeek-R1-Zero 和 DeepSeek-R1 的性能。
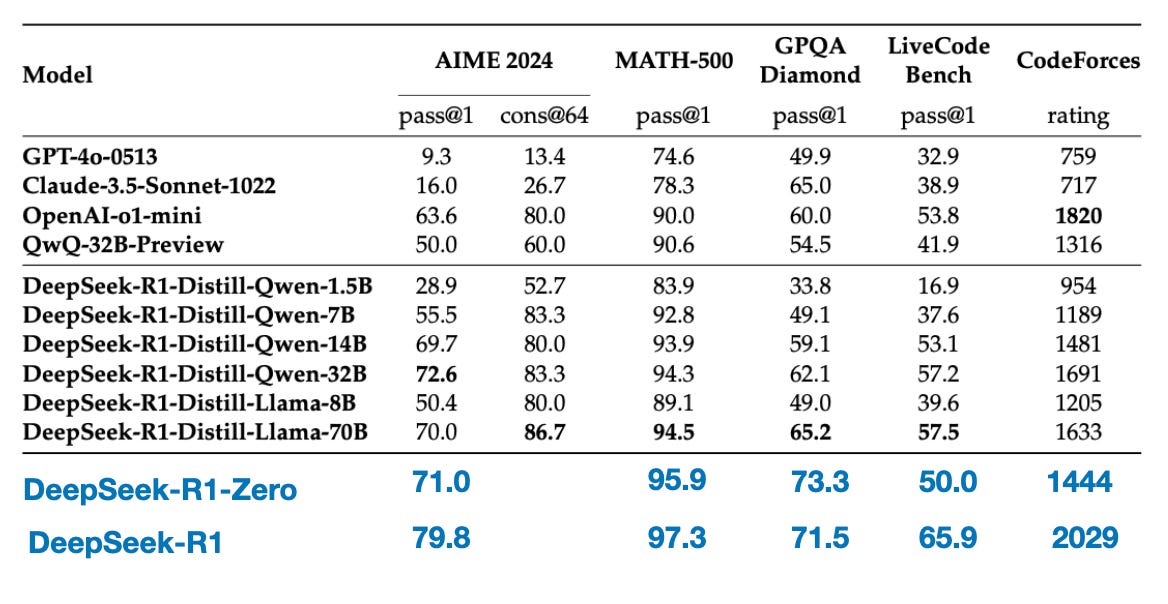
Benchmark comparison of distilled versus non-distilled models. Annotated figure from the DeepSeek-R1 technical report (https://arxiv.org/abs/2501.12948).
蒸馏模型与非蒸馏模型的基准比较。来自 DeepSeek-R1 技术报告 (https://arxiv.org/abs/2501.12948) 的注释图。
As we can see, the distilled models are noticeably weaker than DeepSeek-R1, but they are surprisingly strong relative to DeepSeek-R1-Zero, despite being orders of magnitude smaller. It’s also interesting to note how well these models perform compared to o1 mini (I suspect o1-mini itself might be a similarly distilled version of o1).
正如我们所看到的,蒸馏模型明显比 DeepSeek-R1 弱,但相对于 DeepSeek-R1-Zero 而言,它们出乎意料地强大,尽管它们小了几个数量级。同样有趣的是,与 o1 mini 相比,这些模型的性能如何(我怀疑 o1-mini 本身可能是 o1 的类似蒸馏版本)。
Before wrapping up this section with a conclusion, there’s one more interesting comparison worth mentioning. The DeepSeek team tested whether the emergent reasoning behavior seen in DeepSeek-R1-Zero could also appear in smaller models. To investigate this, they applied the same pure RL approach from DeepSeek-R1-Zero directly to Qwen-32B.
在用结论结束本节之前,还有一个有趣的比较值得一提。DeepSeek 团队测试了在 DeepSeek-R1-Zero 中看到的涌现推理行为是否也可能出现在较小的模型中。为了研究这一点,他们将 DeepSeek-R1-Zero 中相同的纯 RL 方法直接应用于 Qwen-32B。
The results of this experiment are summarized in the table below, where QwQ-32B-Preview serves as a reference reasoning model based on Qwen 2.5 32B developed by the Qwen team (I think the training details were never disclosed). This comparison provides some additional insights into whether pure RL alone can induce reasoning capabilities in models much smaller than DeepSeek-R1-Zero.
此实验的结果总结在下表中,其中 QwQ-32B-Preview 是 Qwen 团队开发的基于 Qwen 2.5 32B 的参考推理模型(我认为训练细节从未公开)。此比较提供了一些额外的见解,即纯 RL 本身是否可以在比 DeepSeek-R1-Zero 小得多的模型中诱导推理能力。
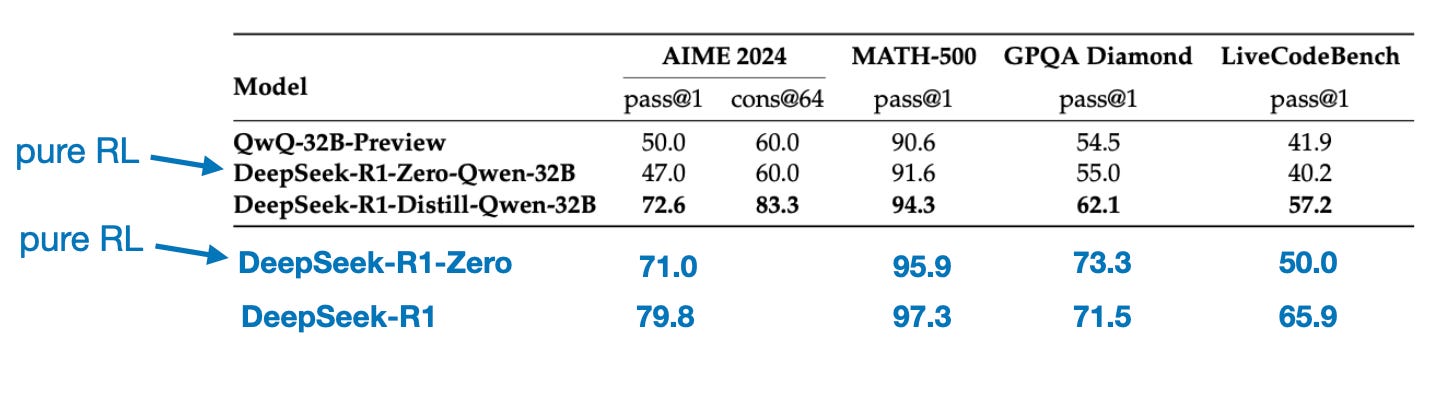
Benchmark comparison distillation and RL on a smaller 32B model. Annotated figure from the DeepSeek-R1 technical report (https://arxiv.org/abs/2501.12948).
在较小的 32B 模型上进行蒸馏和 RL 的基准比较。来自 DeepSeek-R1 技术报告 (https://arxiv.org/abs/2501.12948) 的注释图。
Interestingly, the results suggest that distillation is far more effective than pure RL for smaller models. This aligns with the idea that RL alone may not be sufficient to induce strong reasoning abilities in models of this scale, whereas SFT on high-quality reasoning data can be a more effective strategy when working with small models.
有趣的是,结果表明,对于较小的模型,蒸馏比纯 RL 有效得多。这与这样的观点一致,即对于这种规模的模型,仅靠 RL 可能不足以诱导强大的推理能力,而在高质量推理数据上进行 SFT 可能是使用小型模型时更有效的策略。
For completeness, it would have been useful to see additional comparisons in the table:
为了完整起见,在表中看到更多比较将很有用:
1. Qwen-32B trained with SFT + RL, similar to how DeepSeek-R1 was developed. This would help determine how much improvement can be made, compared to pure RL and pure SFT, when RL is combined with SFT.
- 使用 SFT + RL 训练的 Qwen-32B,类似于 DeepSeek-R1 的开发方式。这将有助于确定当 RL 与 SFT 结合时,与纯 RL 和纯 SFT 相比,可以做出多少改进。
2. DeepSeek-V3 trained with pure SFT, similar to how the distilled models were created. This would allow for a direct comparison to see how effective RL + SFT is over pure SFT.
- 使用纯 SFT 训练的 DeepSeek-V3,类似于蒸馏模型的创建方式。这将允许直接比较,以了解 RL + SFT 比纯 SFT 有效多少。
In this section, we explored four different strategies for building and improving reasoning models:
在本节中,我们探讨了构建和改进推理模型的四种不同策略:
1. Inference-time scaling requires no additional training but increases inference costs, making large-scale deployment more expensive as the number or users or query volume grows. Still, it remains a no-brainer for improving the performance of already strong models. I strongly suspect that o1 leverages inference-time scaling, which helps explain why it is more expensive on a per-token basis compared to DeepSeek-R1.
- 推理时扩展不需要额外的训练,但会增加推理成本,随着用户数量或查询量的增长,大规模部署的成本会更高。尽管如此,它仍然是提高已经很强大的模型性能的不二之选。我强烈怀疑 o1 利用了推理时扩展,这有助于解释为什么与 DeepSeek-R1 相比,它的每个令牌成本更高。
2. Pure RL is interesting for research purposes because it provides insights into reasoning as an emergent behavior. However, in practical model development, RL + SFT is the preferred approach as it leads to stronger reasoning models. I strongly suspect that o1 was trained using RL + SFT as well. More precisely, I believe o1 starts from a weaker, smaller base model than DeepSeek-R1 but compensates with RL + SFT and inference-time scaling.
- 纯 RL 对于研究目的很有趣,因为它提供了关于推理作为一种涌现行为的见解。然而,在实际模型开发中,RL + SFT 是首选方法,因为它会产生更强大的推理模型。我强烈怀疑 o1 也使用了 RL + SFT 进行训练。更准确地说,我认为 o1 从比 DeepSeek-R1 更弱、更小的基础模型开始,但通过 RL + SFT 和推理时扩展来弥补。
3. As mentioned above, RL + SFT is the key approach for building high-performance reasoning models. DeepSeek-R1 is a nice blueprint showing how this can be done.
- 如上所述,RL + SFT 是构建高性能推理模型的关键方法。DeepSeek-R1 是一个很好的蓝图,展示了如何做到这一点。
4. Distillation is an attractive approach, especially for creating smaller, more efficient models. However, the limitation is that distillation does not drive innovation or produce the next generation of reasoning models. For instance, distillation always depends on an existing, stronger model to generate the supervised fine-tuning (SFT) data.
- 蒸馏是一种有吸引力的方法,特别是在创建更小、更高效的模型方面。然而,局限性在于蒸馏不会驱动创新或产生下一代推理模型。例如,蒸馏始终依赖于现有的、更强大的模型来生成监督微调 (SFT) 数据。
One interesting aspect I expect to see next is to combine RL + SFT (approach 3) with inference-time scaling (approach 1). This is likely what OpenAI o1 is doing, except it’s probably based on a weaker base model than DeepSeek-R1, which explains why DeepSeek-R1 performs so well while remaining relatively cheap at inference time.
我期望接下来看到的一个有趣的方面是将 RL + SFT(方法 3)与推理时扩展(方法 1)相结合。这很可能是 OpenAI o1 正在做的事情,只是它可能基于比 DeepSeek-R1 更弱的基础模型,这解释了为什么 DeepSeek-R1 表现如此出色,同时在推理时仍然相对便宜。
In recent weeks, many people have asked for my thoughts on the DeepSeek-R1 models. In short, I think they are an awesome achievement. As a research engineer, I particularly appreciate the detailed technical report, which provides insights into their methodology that I can learn from.
最近几周,很多人问我对 DeepSeek-R1 模型的看法。简而言之,我认为它们是一项了不起的成就。作为一名研究工程师,我特别欣赏详细的技术报告,它提供了有关他们方法的见解,我可以从中学习。
One of the most fascinating takeaways is how reasoning emerged as a behavior from pure RL. And it’s impressive that DeepSeek has open-sourced their models under a permissive open-source MIT license, which has even fewer restrictions than Meta’s Llama models.
最令人着迷的收获之一是推理如何作为一种行为从纯 RL 中涌现出来。令人印象深刻的是,DeepSeek 以宽松的开源 MIT 许可证开源了他们的模型,该许可证的限制甚至比 Meta 的 Llama 模型还要少。
How does it compare to o1?
它与 o1 相比如何?
Is DeepSeek-R1 better than o1? I’d say it’s roughly in the same ballpark. However, what stands out is that DeepSeek-R1 is more efficient at inference time. This suggests that DeepSeek likely invested more heavily in the training process, while OpenAI may have relied more on inference-time scaling for o1.
DeepSeek-R1 比 o1 更好吗?我会说它们大致在同一水平。然而,突出之处在于 DeepSeek-R1 在推理时更有效率。这表明 DeepSeek 可能在训练过程中投入了更多,而 OpenAI 可能更多地依赖于 o1 的推理时扩展。
That said, it’s difficult to compare o1 and DeepSeek-R1 directly because OpenAI has not disclosed much about o1. For instance, we don’t know:
话虽如此,但很难直接比较 o1 和 DeepSeek-R1,因为 OpenAI 没有透露太多关于 o1 的信息。例如,我们不知道:
Is o1 also a Mixture of Experts (MoE)?
o1 也是专家混合 (MoE) 模型吗?
How large is o1?
o1 有多大?
Could o1 just be a slightly refined version of GPT-4o with minimal RL + SFT and only extensive inference-time scaling?
o1 可能只是 GPT-4o 的略微改进版本,具有最少的 RL + SFT 和仅广泛的推理时扩展吗?
Without knowing these details, a direct comparison remains an apples-to-oranges comparison.
在不了解这些细节的情况下,直接比较仍然是苹果与橙子的比较。
The cost of training DeepSeek-R1
训练 DeepSeek-R1 的成本
Another point of discussion has been the cost of developing DeepSeek-R1. Some have mentioned a ~$6 million training cost, but they likely conflated DeepSeek-V3 (the base model released in December last year) and DeepSeek-R1.
另一个讨论点是开发 DeepSeek-R1 的成本。有些人提到约 600 万美元的训练成本,但他们可能混淆了 DeepSeek-V3(去年 12 月发布的基础模型)和 DeepSeek-R1。
The $6 million estimate is based on an assumed $2 per GPU hour and the number of GPU hours required for the final training run of DeepSeek-V3, which was originally discussed back in December 2024.
600 万美元的估算基于假定每 GPU 小时 2 美元以及 DeepSeek-V3 的最终训练运行所需的 GPU 小时数,这最初在 2024 年 12 月讨论过。
However, the DeepSeek team has never disclosed the exact GPU hours or development cost for R1, so any cost estimates remain pure speculation.
然而,DeepSeek 团队从未透露 R1 的确切 GPU 小时数或开发成本,因此任何成本估算都仍然是纯粹的猜测。
Either way, ultimately, DeepSeek-R1 is a major milestone in open-weight reasoning models, and its efficiency at inference time makes it an interesting alternative to OpenAI’s o1.
无论如何,最终,DeepSeek-R1 是开放权重推理模型的一个重要里程碑,它在推理时的效率使其成为 OpenAI 的 o1 的一个有趣的替代方案。
Developing a DeepSeek-R1-level reasoning model likely requires hundreds of thousands to millions of dollars, even when starting with an open-weight base model like DeepSeek-V3. This can feel discouraging for researchers or engineers working with limited budgets.
即使从像 DeepSeek-V3 这样的开放权重基础模型开始,开发 DeepSeek-R1 级别的推理模型也可能需要数十万到数百万美元。这对于预算有限的研究人员或工程师来说可能会感到沮丧。
The good news: Distillation can go a long way
好消息:蒸馏可以发挥很大作用
Fortunately, model distillation offers a more cost-effective alternative. The DeepSeek team demonstrated this with their R1-distilled models, which achieve surprisingly strong reasoning performance despite being significantly smaller than DeepSeek-R1. However, even this approach isn’t entirely cheap. Their distillation process used 800K SFT samples, which requires substantial compute.
幸运的是,模型蒸馏提供了一种更具成本效益的替代方案。DeepSeek 团队通过他们的 R1 蒸馏模型证明了这一点,这些模型尽管比 DeepSeek-R1 小得多,但仍实现了令人惊讶的强大推理性能。然而,即使这种方法也并非完全便宜。他们的蒸馏过程使用了 80 万个 SFT 样本,这需要大量的计算。
Interestingly, just a few days before DeepSeek-R1 was released, I came across an article about Sky-T1, a fascinating project where a small team trained an open-weight 32B model using only 17K SFT samples. The total cost? Just $450, which is less than the registration fee for most AI conferences.
有趣的是,就在 DeepSeek-R1 发布前几天,我偶然发现了一篇关于 Sky-T1 的文章,这是一个令人着迷的项目,一个小团队仅使用 1.7 万个 SFT 样本就训练了一个开放权重的 32B 模型。总成本是多少?仅 450 美元,这低于大多数人工智能会议的注册费。
This example highlights that while large-scale training remains expensive, smaller, targeted fine-tuning efforts can still yield impressive results at a fraction of the cost.
这个例子突显出,虽然大规模训练仍然昂贵,但较小规模、有针对性的微调工作仍然可以以一小部分成本产生令人印象深刻的结果。
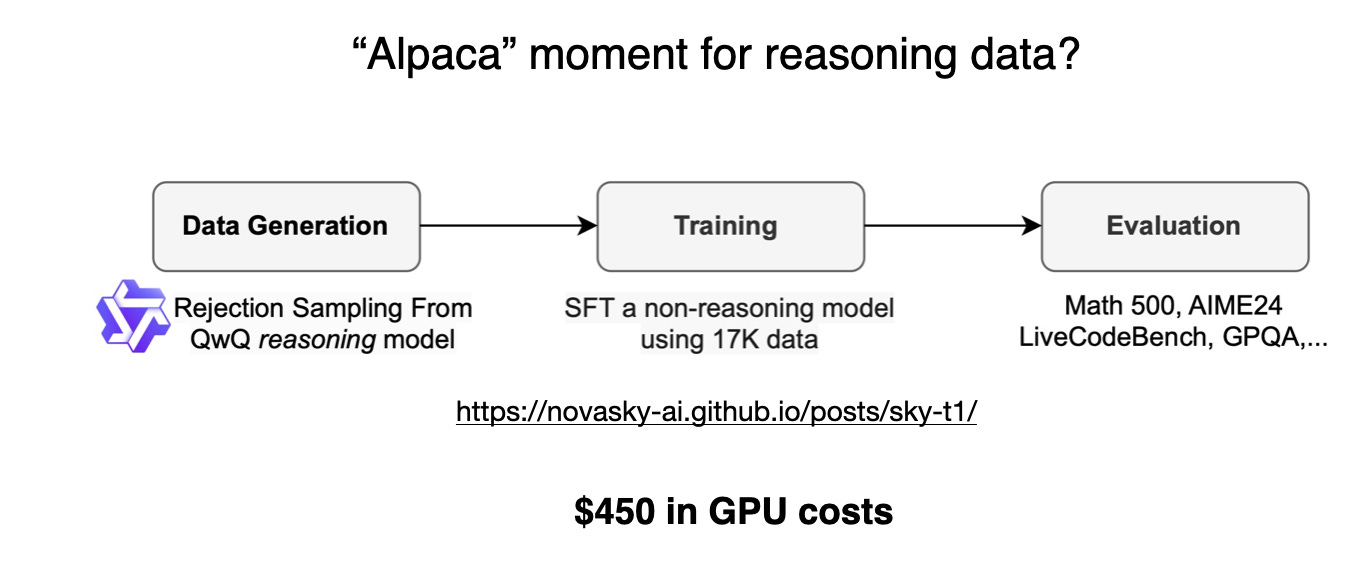
Figure from the “Sky-T1: Train your own O1 preview model within $450” article, https://novasky-ai.github.io/posts/sky-t1/
来自文章“Sky-T1:在 450 美元内训练您自己的 O1 预览模型”的图,https://novasky-ai.github.io/posts/sky-t1/
According to their benchmarks, Sky-T1 performs roughly on par with o1, which is impressive given its low training cost.
根据他们的基准测试,Sky-T1 的性能与 o1 大致相当,考虑到其低廉的训练成本,这令人印象深刻。
Pure RL on a budget: TinyZero
预算有限的纯 RL:TinyZero
While Sky-T1 focused on model distillation, I also came across some interesting work in the “pure RL” space. One notable example is TinyZero, a 3B parameter model that replicates the DeepSeek-R1-Zero approach (side note: it costs less than $30 to train).
虽然 Sky-T1 专注于模型蒸馏,但我也在“纯 RL”领域发现了一些有趣的工作。一个值得注意的例子是 TinyZero,这是一个 3B 参数模型,它复制了 DeepSeek-R1-Zero 方法(旁注:训练成本不到 30 美元)。
Surprisingly, even at just 3B parameters, TinyZero exhibits some emergent self-verification abilities, which supports the idea that reasoning can emerge through pure RL, even in small models.
令人惊讶的是,即使只有 3B 参数,TinyZero 也表现出一些涌现的自我验证能力,这支持了推理可以通过纯 RL 涌现的观点,即使在小型模型中也是如此。
The TinyZero repository mentions that a research report is still work in progress, and I’ll definitely be keeping an eye out for further details.
TinyZero 存储库 提到研究报告仍在撰写中,我肯定会密切关注更多细节。

A figure from the TinyZero repository (https://github.com/Jiayi-Pan/TinyZero) showing that the model is capable of self-verification. (It would have been interesting to see the response of the base model in comparison.)
来自 TinyZero 存储库 (https://github.com/Jiayi-Pan/TinyZero) 的图,显示该模型能够进行自我验证。(比较一下基础模型的响应会很有趣。)
The two projects mentioned above demonstrate that interesting work on reasoning models is possible even with limited budgets. While both approaches replicate methods from DeepSeek-R1, one focusing on pure RL (TinyZero) and the other on pure SFT (Sky-T1), it would be fascinating to explore how these ideas can be extended further.
上面提到的两个项目表明,即使预算有限,推理模型方面的有趣工作也是可能的。虽然这两种方法都复制了 DeepSeek-R1 的方法,一种侧重于纯 RL (TinyZero),另一种侧重于纯 SFT (Sky-T1),但探索如何进一步扩展这些想法将非常有趣。
Beyond Traditional SFT: Journey Learning
超越传统 SFT:旅程学习
One particularly interesting approach I came across last year is described in the paper O1 Replication Journey: A Strategic Progress Report – Part 1. Despite its title, the paper does not actually replicate o1. Instead, it introduces an different way to improve the distillation (pure SFT) process.
去年我偶然发现的一种特别有趣的方法在论文 O1 复制之旅:战略进展报告 – 第 1 部分 中进行了描述。尽管标题如此,但该论文实际上并没有复制 o1。相反,它介绍了一种改进蒸馏(纯 SFT)过程的不同方法。
The key idea in the paper is “journey learning” as an alternative to “shortcut learning.”
该论文中的关键思想是“旅程学习”,作为“捷径学习”的替代方案。
Shortcut learning refers to the traditional approach in instruction fine-tuning, where models are trained using only correct solution paths.
捷径学习指的是指令微调中的传统方法,其中模型仅使用正确的解决方案路径进行训练。
Journey learning, on the other hand, also includes incorrect solution paths, allowing the model to learn from mistakes.
另一方面,旅程学习也包括不正确的解决方案路径,允许模型从错误中学习。
This approach is kind of related to the self-verification abilities observed in TinyZero’s pure RL training, but it focuses on improving the model entirely through SFT. By exposing the model to incorrect reasoning paths and their corrections, journey learning may also reinforce self-correction abilities, potentially making reasoning models more reliable this way.
这种方法有点类似于在 TinyZero 的纯 RL 训练中观察到的自我验证能力,但它侧重于完全通过 SFT 改进模型。通过让模型接触不正确的推理路径及其更正,旅程学习也可能增强自我纠正能力,从而可能使推理模型更可靠。
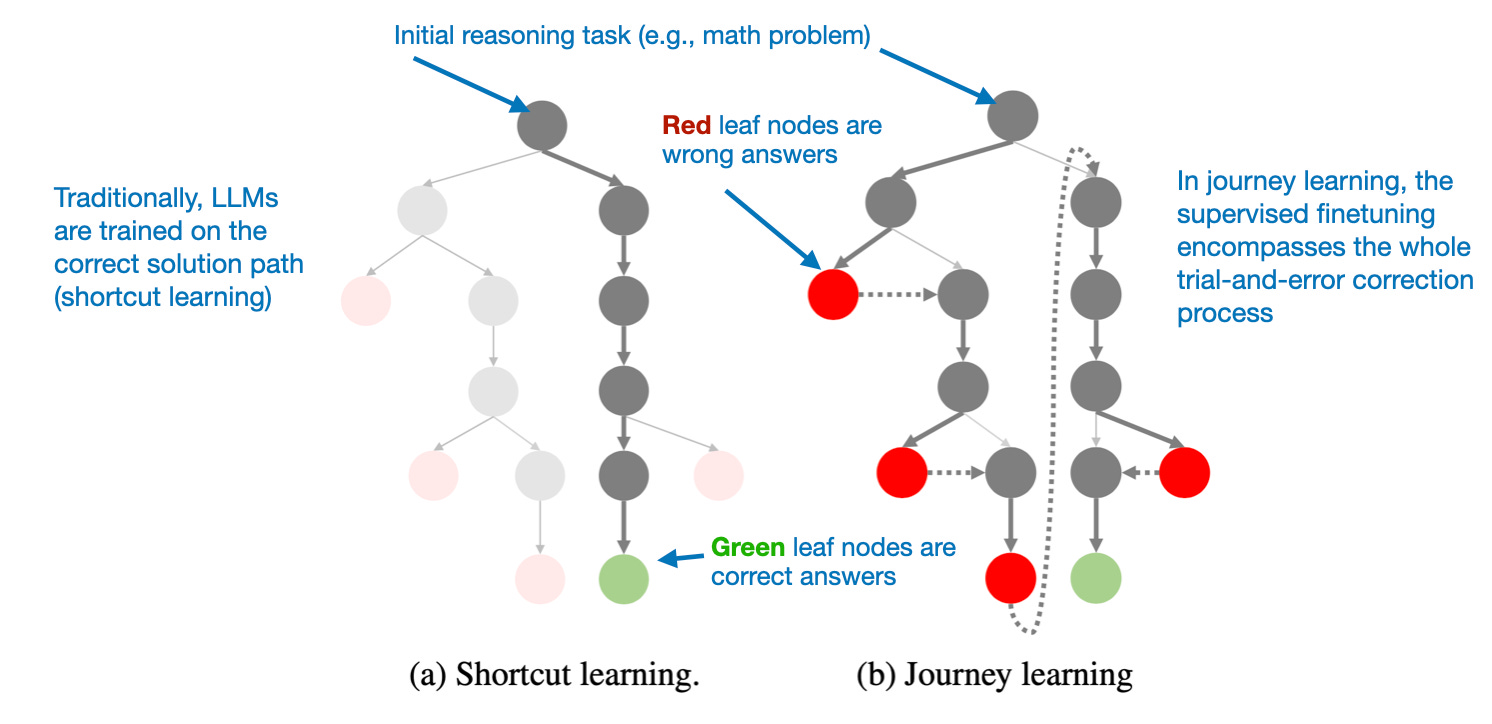
Journey learning, as opposed to traditional shortcut learning, includes wrong solutions paths in the SFT data. Annotated figure from the O1 Replication Journey: A Strategic Progress Report – Part 1 (https://arxiv.org/abs/2410.18982)
旅程学习与传统的捷径学习相反,它在 SFT 数据中包含错误的解决方案路径。来自 O1 复制之旅:战略进展报告 – 第 1 部分 (https://arxiv.org/abs/2410.18982) 的注释图
This could be an exciting direction for future work, particularly for low-budget reasoning model development, where RL-based approaches may be computationally impractical.
这可能是未来工作的一个令人兴奋的方向,特别是对于低预算推理模型开发而言,在这些领域,基于 RL 的方法可能在计算上不切实际。
Anyways, a lot of interesting work is currently happening on the reasoning model front, and I’m sure we will see a lot more exciting work in the upcoming months!
无论如何,目前在推理模型方面正在进行许多有趣的工作,我相信在未来几个月内我们将看到更多令人兴奋的工作!